CheckMag | Sin GPU, no hay problema. Hospedar su propio LLM es infinitamente más divertido que las ofertas censuradas de las grandes empresas y funciona sorprendentemente bien.

Lo que ocurre realmente con sus datos cuando consulta a una IA es prácticamente una incógnita, pero pase lo que pase con ellos, desde luego ya no son suyos.
Junto a imagen y vídeo, si le apetece experimentar con los Modelos de Lenguaje Amplio (LLM), pero no quiere entregar sus datos a las grandes tecnológicas, alojar los suyos propios es sorprendentemente fácil y tiene varias ventajas sobre los grandes actores.
En primer lugar, independientemente de lo que decida hacer con ellos, todos sus datos permanecen bajo su control, lo que, si no está dispuesto a entregar sus datos a Mechahitleres una ventaja inmediata. También puede utilizar prácticamente cualquier modelo que desee, ya sea Deepseek, Gemma2 o GPT, con la ventaja añadida de poder utilizar versiones que no restringirán los tipos de consultas que le lance.
KoboldCPP es una herramienta de generación de textos de inteligencia artificial fácil de usar y ejecutable una sola vez, diseñada para ejecutar grandes modelos lingüísticos GGUF y GGML. Es compatible tanto con la GPU como con la CPU y puede actuar como backend especializado para la narración y el chat de IA. KoboldCPP puede descargarse de GitHub aquí y está disponible para Windows, Linux, Mac o Docker.
Alojarlo en un contenedor hace que sea trivial exponer el LLM a todos los dispositivos de su red, y existen plantillas preconstruidas para las principales plataformas, incluyendo Unraid y TrueNAS. Lo mismo puede conseguirse con otras instalaciones siempre que añada las reglas necesarias a su cortafuegos.
Cómo empezar
Una vez que haya decidido la plataforma de su elección, tendrá que decidir qué modelo utilizar. Hugging Face es el mejor lugar para buscar modelos, y tendrán que estar en formato GGUF.
Si está planeando albergar escenarios de D&D, definitivamente querrá un modelo sin censura, de lo contrario, el LLM se negará en última instancia a dañar a cualquiera de los personajes, y puede generar resultados indeseables resultados.
Algunos modelos, como Deepseek y Claude, tienen propensión a "pensar", lo que básicamente vomita todo el proceso de pensamiento de su consulta. Esto podría estar bien con una GPU haciendo el trabajo pesado, pero sin una ralentiza el proceso considerablemente. Tendrá que experimentar con los modelos para encontrar uno que le funcione, pero Gemma2 es un buen sitio para empezar.
Busque la página de archivos y copie la URL que enlaza con el archivo GGUF. Muchos modelos tienen varios tamaños, por lo que tendrá que elegir uno que se ajuste a las limitaciones de su memoria RAM disponible.
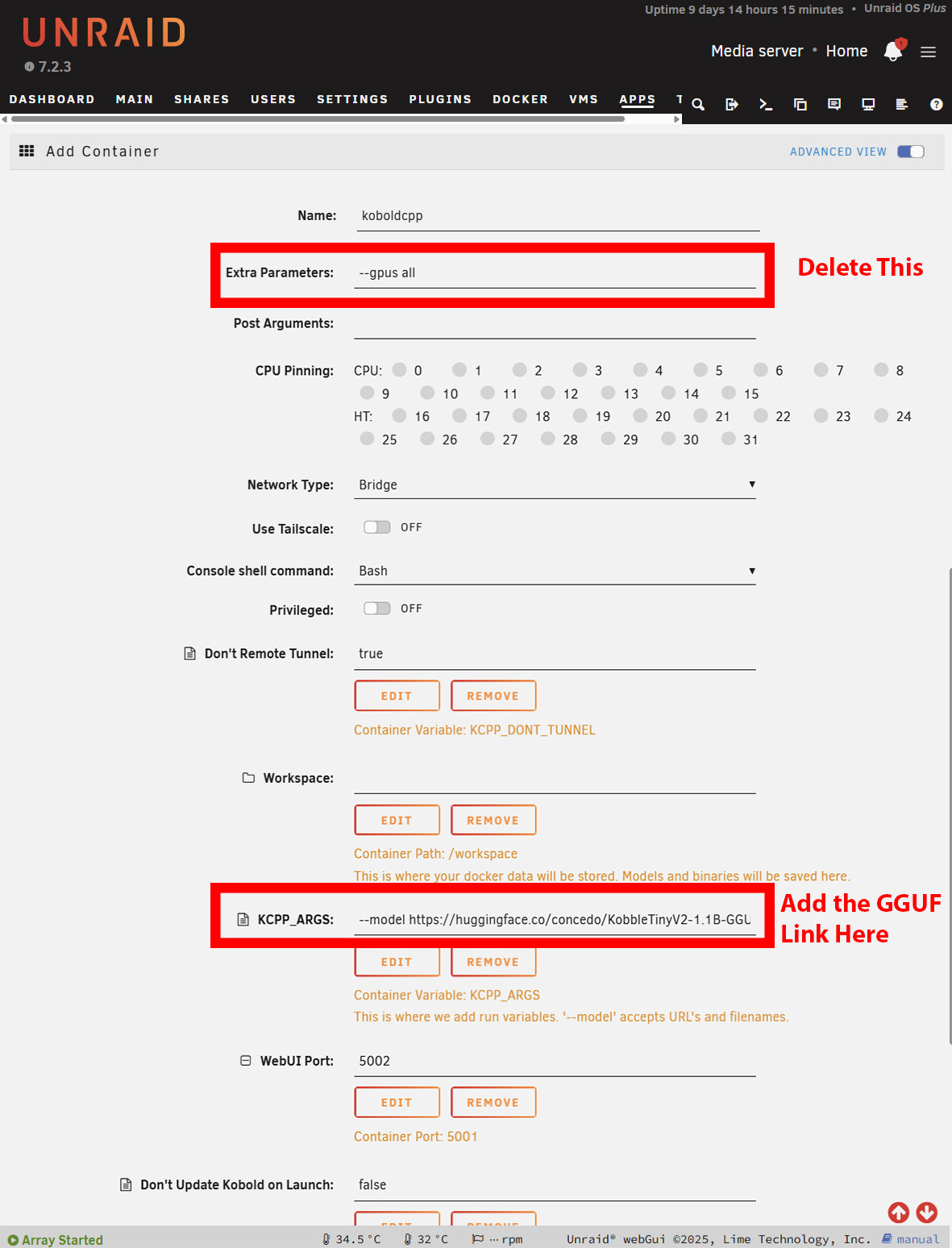
La instalación en Windows es prácticamente la misma. Sin embargo, tendrá que descargar la versión NoCUDA si lo utiliza sin GPU. Puede tardar un poco en iniciarse, ya que KoboldCPP descargará el modelo antes de presentarle la interfaz. En Windows, esto es obvio, pero en Unraid o TrueNAS, tendrá que abrir los registros para ver el progreso de la descarga. En Unraid, es posible que tenga que aumentar el almacenamiento disponible de los contenedores Docker en función del tamaño del modelo elegido.
KoboldCPP ofrece 4 modos de interfaz diferentes, incluyendo instrucciones, historia, chat y aventura.
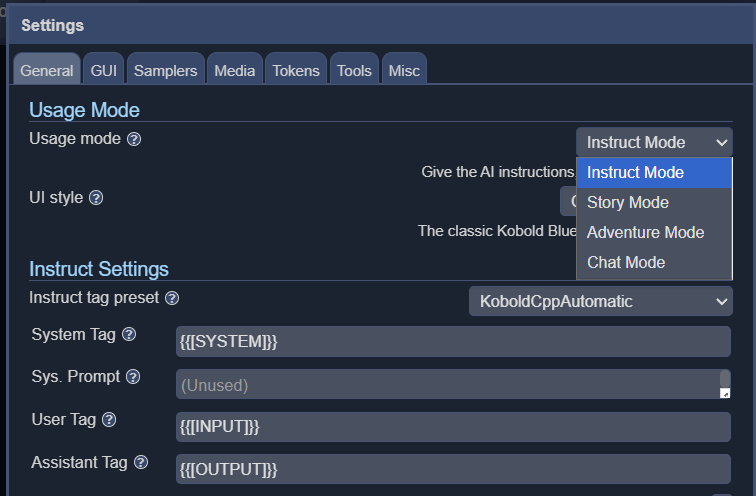
Aunque no es el más rápido ni mucho menos, el texto se genera ligeramente más despacio que la velocidad media de lectura. Perfectamente útil para escenarios de D&D cuando se ejecuta en un AMD 5950x de 16 núcleos(disponible en Amazon) y probablemente funcionará más rápido en CPUs más modernas. Cuantos más núcleos pueda lanzarle, mejor, y una cantidad decente de RAM le permitirá ejecutar modelos más grandes, aunque debería estar bien con 16GB. El tamaño y el tipo de modelo también tendrán un impacto significativo en la velocidad de generación, y elegir un modelo más ligero puede aumentar significativamente la velocidad general.
Obviamente, para obtener la mejor experiencia, lo óptimo es ejecutar los modelos de gran tamaño con una GPU; sin embargo, si le apetece probar a alojar los suyos propios, saltándose las restricciones o las implicaciones para la privacidad de los datos de ChatGPT, Claude o Géminis, no necesita ningún hardware lujoso para empezar y podrá obtener una experiencia decente.
Fuente(s)

