Un idioma sorprendente supera al inglés y al chino en los exámenes LLM, según un nuevo estudio académico
Un nuevo estudio multilingüe que evalúa cómo los grandes modelos lingüísticos manejan los documentos largos ha arrojado un dato inesperado: El polaco, y no el inglés o el chino, muestra la mayor precisión cuando las ventanas de contexto se extienden hasta 64.000 tokens y más. Los resultados proceden de la prueba de referencia OneRuler presentada en un documento del COLM 2025en el que se probaron 26 idiomas en tareas de recuperación y agregación.
Los investigadores compararon la precisión de los modelos con distintas longitudes de contexto y descubrieron un claro cambio una vez que las secuencias se hacían más largas. Según la tabla de resultados (en la página 6), el polaco lidera todas las lenguas con una precisión media del 88% a escalas de contexto largas. El inglés cae al sexto puesto y el chino se sitúa entre los cuatro últimos.
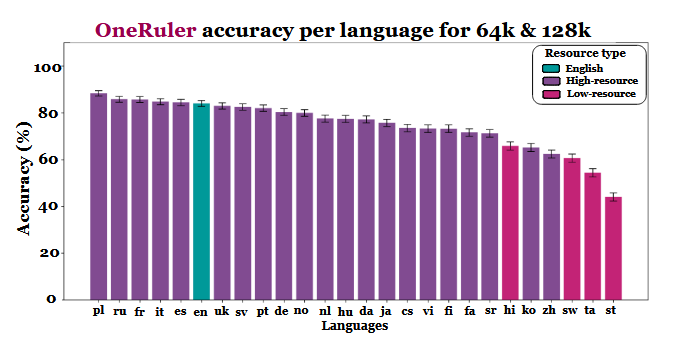
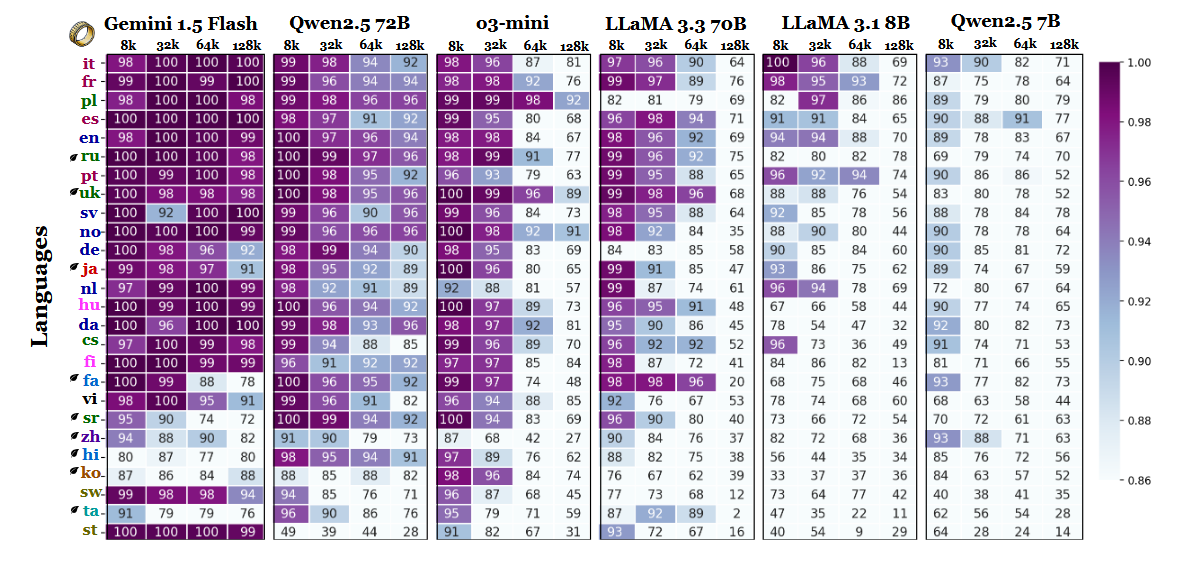
El estudio insinúa que la disparidad puede estar ligada a la eficacia de la tokenización y a las diferencias basadas en la escritura, más que al simple volumen de datos de entrenamiento. Las lenguas que utilizan escrituras basadas en el latín -como el polaco, el francés y el español- obtuvieron sistemáticamente mejores resultados que las que emplean sistemas de escritura logográfica o abugida. El chino, el coreano, el tamil y otros sólo mostraron una precisión moderada incluso en contextos más cortos (y su precisión se deterioró aún más a medida que las secuencias se hacían más largas). Este completo giro de 180 grados de las clasificaciones esperadas es interesante, porque la mayoría de los LLM de uso generalizado se entrenan principalmente en conjuntos de datos con un alto contenido de inglés. Sin embargo, los resultados del trabajo indican que una vez que los modelos deben buscar, recuperar o resumir información enterrada en documentos largos, los aspectos estructurales de la lengua tienen preferencia sobre la prevalencia del conjunto de datos.
Otras conclusiones de la comparativa también apoyan esta interpretación. La diferencia de rendimiento entre las lenguas más fuertes y las más débiles crece bruscamente a medida que se amplía el contexto: del 11% a 8.000 tokens al 34% a 128.000 tokens. Otro detalle del estudio muestra lo sensibles que pueden ser estas pruebas a pequeños cambios en las instrucciones. Por ejemplo, el simple hecho de permitir que el modelo responda "ninguno" si falta una cadena objetivo hizo que la precisión en inglés cayera un 32% a 128.000 tokens, como puede verse en la página 2.
Aunque la prueba comparativa también compara familias de modelos, los resultados implican que la evaluación de contextos largos no puede basarse únicamente en pruebas en inglés y que las generalizaciones de rendimiento entre idiomas pueden ser engañosas si se ignoran los efectos de la escritura y la tokenización. A medida que las ventanas de contexto se hacen más grandes, las diferencias lingüísticas se hacen más importantes, no menos - y el dominio del inglés en los puntos de referencia LLM puede dejar de ser representativo una vez que las longitudes de secuencia suban a las decenas de miles.
Fuente(s)
Una regla para medirlos a todos: Evaluación comparativa de modelos lingüísticos multilingües de contexto largo en COLM 2025
Imagen destacada de Zulfugar Karimov en Unsplash

